
Designing for web3: thoughts from first principles
Thoughts and other notes on the first principles of UX design in web3

A lot of things are being written every day on Twitter about this new digital world built on the premise of ownership and decentralization. I’ve been into crypto for a while and I’ve been amazed at how everyone is enthusiastically pushing this grand vision forward. Yet, the experience of that vision through the products that we are building is quite underwhelming.
To be clear: I’m not saying it with any kind of sarcasm or skepticism, but I mean it.
We regularly see terrible user experiences and quite confusing web3 products that ignore even basic best practices. How come?
Is it because there are fundamental technical constraints that require a greater surface complexity or is it because we haven’t done the effort to think about new perspectives? Or maybe worse: is it because web3 builders aren’t just interested in lessons from the past?
I get that breaking from old standards is core to the web3 DNA but are we really sure that everything should be a candidate for a “revolutionary” redesign? The underlying technology might be able to do things that have never been imaginable before, but the average users don't quite get it, let alone use it.
I’m convinced that these aren’t obvious questions. They aren’t obvious because for the first time in a while we’re dealing with a new category of people on the internet. It’s not just about technology, it’s about behaviors and idealogy and identity. And designing things for people with polarized natures is intrinsically hard.
I wanted to write a piece to get to the essence of this new wave of technology and products from a design standpoint. And from there, try to derive some simple, clear, and understandable first principles that hopefully can serve to others as fundamentals for what’s ahead.
This might be one of those pieces that are easy to disagree with. Nevertheless, it is an attempt, an essay as Paul Graham would say, to understand a thing that is worth exploring.
It is an ambitious goal, so let’s start from the basics: what is “web3” and what is fundamentally new about it?
Web3 – a premise
Let’s just say that web3 is a somewhat ambiguous rebranding of “crypto”.
The general definition seems to be that web1 (we’re talking 90s and early '00s) was the internet era of open protocols: TCP/IP for data transfer, HTTP for hyperlinks, SMTP for email, RSS for web content aggregation, etc. Everything was decentralized and community-governed.
These shared protocols produced immeasurable amounts of value, but most of it got captured and “re-aggregated” at the application layer by the next generation of companies (Facebook, Twitter, Google, Amazon, and most of today’s tech giants). And this period of time that started around 2002 or so, is referred to as web2.
Finally, web3 is the latest stage of the internet evolution. It’s where things should get decentralized again with open protocols and community-run networks, combining the open infrastructure of web1 with the public participation of web2.
Exciting? Yes, but also vague.
So let’s go deeper. What are the core elements that make this new wave of technology fundamentally different from everything that came before?
In my mind, the answer has 2 distinct facets. There’s a technical reason and an ethical one.
Technical differences
Web3 promotes a new kind of internet app (or better say dapps: decentralized applications) predicated on the basis of decentralized computing. Instead of relying on the computation power that comes from a single, central location, they’re powered by a peer-to-peer network of computers, called blockchain.
On the surface, there’s nothing particularly different about web3 distributed applications: they’re just normal react websites. In fact, the vast majority of these decentralized apps (I’m thinking of OpenSea, Rarible, and the hundreds of similar marketplaces) host their frontend architecture on centralized cloud providers like Google Cloud or AWS, and often, due to performance and scalability reasons, they have meaningful off-chain components. (This is going to be an important point later!)1
The “distributed” aspect refers to where the state and the business logic for updating the state live: on the blockchain instead of in a “centralized” database.
This means that you wouldn’t actually need the frontend for the core functionality to stay intact and that potentially anyone could make their own frontend.
This is actually possible because of this underlying piece of technology called blockchain, and its special properties:
Public: everyone in the public blockchain can see the history of transactions since its inception. Everything is transparent.
Immutable: every node on the system has a copy of the digital ledger. To add a transaction every node needs to check its validity. If the majority thinks it’s valid, then it’s added to the ledger.
Trustless: it gets rid of the need for a sovereign authority – no one can just simply change any characteristics of the network for their benefit.
Decentralized: the network is decentralized meaning it doesn’t have any governing authority or a single person looking after the framework. Rather there’s just a group of computer nodes that maintain the network up and running.
There’s a fifth property that is often overlooked: composability. The fact that these dapps rely on open backends disrupts in a very fundamental way how different pieces of software interact with each other.
Today you can make Stripe talk to Shopify or any other apps using their APIs. Different apps can establish a relationship if they agree on the same contract and the same terms (limit rates, access, permissions, etc). But here’s the catch: this relationship is expressed through a (fragile) mutual dependency that can break at any time as more apps are involved and the underneath complexity increases.
Conversely, when the app backend lives on a shared blockchain you can write programs that interface natively with other programs on it. One Solidity program can call another at any time and without cross-dependencies between different apps.
This is what makes it easy to package, route, and pipe credits and debits across all kind of protocols and DeFi apps. Just as it makes it easy to create interoperable social mechanics and composable community commerce experiences through social gating and NFTs.2
Ethical differences
Many said that the concept of Bitcoin was conceived in 2008, as a response to the great recession and the financial world’s reliance on banks as intermediaries of all financial transactions. That’s inaccurate, but not entirely wrong.
The financial crisis was not the reason for Bitcoin (Satoshi started working on it back in 2007) but it certainly was a symptom.
The goal of creating this sound digital cash system was to remove the third-party intermediaries that are traditionally required to conduct digital monetary transfers. Decentralization as a means of monetary independence was the main motivation.
It was until 2015, with Ethereum and the first “programmable” on-chain environment, that the idea of crypto as a decentralization force for other – non-financial – use cases, started to develop.
Ethereum opened the door to a world of new possibilities and developers stepped inside.
Inside that world, agreements (specifically, smart contracts), could be “programmed” and “executed” in a trustless and transparent way leveraging consensus and incentive-based mechanisms.
It became clear that cryptonetworks could fix many of the centralization problems created by the previous generation of internet companies. Economic incentives to developers, maintainers, and other network participants in the form of tokens could align network participants to work together toward a common goal — the growth of the network and the appreciation of the token.
It is here that the ideology of decentralization morphed into a number of other things. Not just monetary independence but also deconcentration of centralized structures for a more transparent approach to decision-making; and the inclusion of multiple interest bearers to find consensus-based solutions to common problems.
Web3 and Design
It’s important to understand the technical and ethical differences of web3 because they define the laws of physics of this new world; and that’s a prerequisite if we want to shape the experiences of its inhabits.
Part I: “Don’t trust me; trust the blockchain”
Crypto is fundamentally a kind of behavior, just as much or arguably even more than it is a kind of technology. There are many facets to this behavior, but it starts from cryptography; and it starts with one core belief: users trust what they believe it’s true; and they believe it’s true if it’s on the blockchain.
As we said earlier, blockchains aren’t just open source, but also open state entities. To put it in another way, the state of the users (eg. who owns what, who spent what, who voted what, etc) and the codified agreements that determine the conditions under which those states are resolved, are both open and accessible to everyone.
One can simplify by saying that all decentralized applications (DeFi, wallet clients, NFT marketplaces, exchanges, etc) are front-ends, and the blockchain is the backend – but here’s where things get tricky. Not every decentralized app interacts with the underlying blockchain in the same way.
Some decentralized apps are one-to-one proxies of the blockchain. Basically, most of what the user can do at the application layer is fully reflected in the underneath blockchain.
Other decentralized apps are a mix of on-chain and off-chain code. The low-level logic and the key critical components are on-chain and the marginal, less-important features that aren’t critical for the app to function are kept off-chain.
For example: imagine you want to build a decentralized Twitter alternative. The registry (where users can claim a unique @username) is the only part of the network that really needs to be synchronized on a blockchain. All other actions, like where the user stores their social data, the various algorithms that power the platform (eg. feed, trends, ranking, recommendations, etc), or, strictly speaking, any other sort of thing that requires heavy computation and storage, can securely happen off-chain. Without the front-end app, you would miss some features but none of them would prevent you from using the service under your own (or a third-party) client.
And, eventually, there’s a third category of decentralized apps. These apps have only a small portion of their logic on-chain. Most of the code lives on a central database that sits on a private (cloud or not) infrastructure. I’m thinking of certain exchanges that interact with the blockchain only at the settlement layer or certain apps that provide tokens to users, but the product itself isn't really open.
So, going back to the premise, if we agree that “users trust what they believe it’s true; and they believe it’s true if it’s on the blockchain,” – we must also agree that a trustworthy web3 product shouldn’t in any way blur, obfuscate or confuse the “origin” of its data.
This idea has many implications, so let’s unpack it.
1.1 Explicit Data Provenance
As we just saw, there are 2 kinds of data in dapps: application data and blockchain data. Application data are off-chain data that are computed on servers. These data typically don’t interact with the blockchain and if they do is only through oracle services (eg. Chainlink). On the other hand, blockchain data lives persistently on the distributed ledger that runs on every node of the network.
The important principle to appreciate here is that these are 2 separate classes of data. One that is secure and verifiable, and one that is not. So, it can’t be considered a regular design practice let users “guess” where the data comes from. And most importantly, it can’t let them assume that all data seen is stored in the blockchain, because - as it turns out - it is rarely the case.
Acknowledging this distinction gets even more relevant when the user starts acting up and tries to alter those data by signing off transactions or calling smart-contract functions.
In most decentralized apps that I’ve seen the only thing that is telling the users “Hey, you're about to permanently modify some stuff at the blockchain layer“ is the wallet client interaction that sign-offs the hash with the local private key.
There’s a lot that can be written in terms of design ideas on this aspect alone, but here are some of the things I've been pondering:
CSS styles to change the color or font to distinguish blockchain vs application data
Contextual tooltips so that when hovering or clicking on a blockchain data point, you can provide a contextual area with more information about the provenance of the data
1.2 Vocabulary consistency
I’ve seen many research-based academic papers recommending that future wallet clients should mimic the functionality of traditional payment systems and avoid specific terms like staking, swapping, farming, etc.
I get the point that making crypto more accessible to average users is a crucial topic, but crypto is also self-identification, and watering down the vocabulary comes at a cost.
If you want users to trust your product, you need to speak their lingo and crypto has the most peculiar lingo of all. It starts right there when you signup for a web3 product, and it starts with the words: “connect wallet.“ Not “Sign up,” not “Create account” and certainly not other fanciness like “Get in there“ or “Get started“.
To the average user “Connect wallet” is probably the scariest way to frame signing up imaginable, but to crypto users, that’s a way of saying “we actually get it.“
In Danco’s words, for crypto users “connect wallet“ is another way of fitting in as citizens of the broader crypto population. “Connect wallet” excites them “sign up to create an account“ exhausts them.
1.3 Users’ expectation management
The history of computing teaches us that novel properties often come with trade-offs. In the case of the blockchain, the fact that you can make verifiable long-term commitments to users comes at the cost of performance and scalability.
There are performance issues because any kind of on-chain computation is slow and expensive. Think of executing code like a crippled and extremely costly version of AWS Lambda. And there are also scalability issues because the Ethereum network can process only 15 transactions per second. As more decentralized apps are built on the network and the number of transactions increases, so do the gas fees.
In short: what gets computed off-chain is fast and potentially close to real-time; what gets computed on-chain is slow and asynchronous.3
I know this might sound a little ridiculous, but this duality of the speed of interactions can create divergent user expectations. Think about using a product that feels sometimes fast and snappy, other times cumbersome and unreasonably slow. How would you feel?
Frustrated? Probably; and even more so - back to our previous points - when the lingo doesn’t add up and you don’t know if the terms you see actually mean what you think they mean.
These issues can be probably mitigated in a number of ways. I’m thinking of progress indicators, multi-step progress bars, ETAs and delay suggestions, etc.
Part II: The crypto-knowledge gap
Crypto attracts polarized users: the power users and the marginalized ones. The crypto enthusiasts that believe in the value of the technology and its ideological underpinnings on one side, and the people who are looking for viable alternatives to their unstable economic circumstances, on the other. And then, if we truly believe in crypto as something with mass-market potential, there’s every other possible category of people in between.
How do you even conceive a product for such a diversified pool of users where what excites some frightens others? How do you fill the knowledge gaps? And how do you feel the emotional gaps?
These are actually complex, hard challenges, but for one thing - they’re not novel. We’ve navigated similar problems in the software revolution, with PCs, early browsers, online payments, and then social networks, mobile, etc. It was always a question, of how we take this piece of technology and make it accessible to more humans.
Jared Spool at UIE has an interesting way of talking about how to build products and fill knowledge gaps.
Say you want to build a product and there are 3 hypothetical categories of users: (A) cypherpunks, (B) hodlers, and (C) newbies. Cypherpunks are subject-matter experts, hodlers are crypto-fluent people, and newbies are curious people, interested in the ecosystem but they don’t seem comfortable even with the simplest operations.
Imagine a spectrum where you’ll line up all these users. On the left side, we’ll put everyone who knows absolutely nothing about how to use our product’s interface. On the right side, we’ll put everyone who knows everything there is to know about the design.
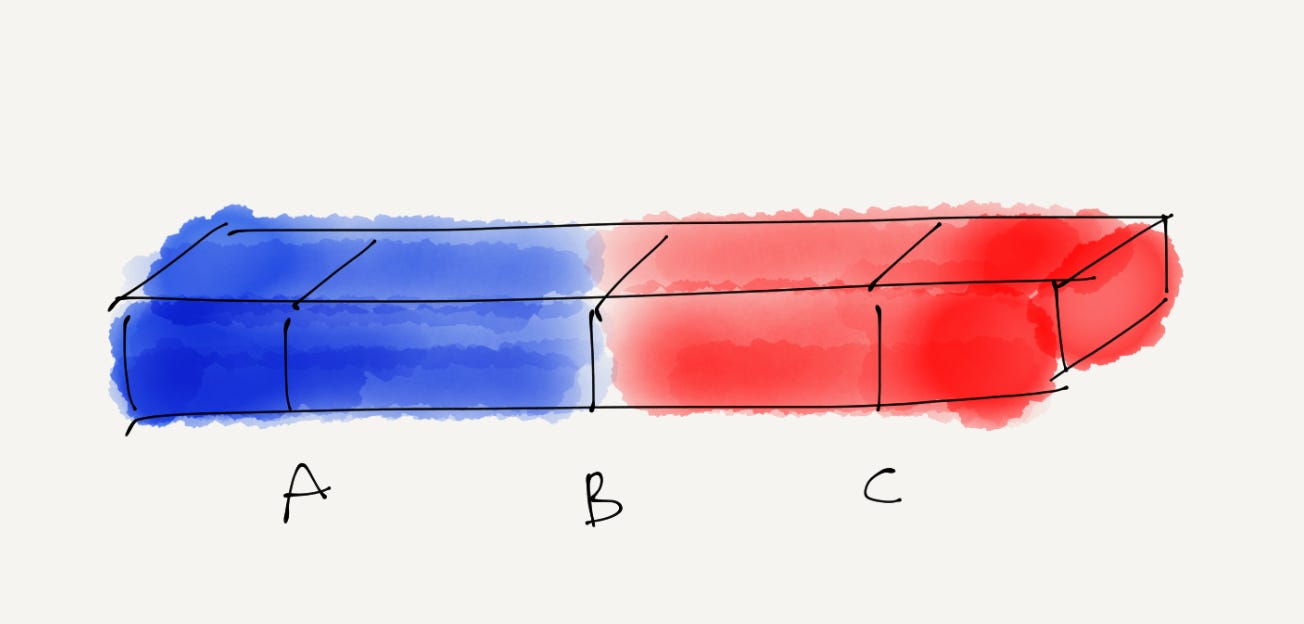
We’ll organize all the users along the wall by how much they know. If they know only a little, they’ll stand closer to the left. The more they know, the closer we put them to the right.
Now let’s add one more point to this wall: the target knowledge point. This point represents how much knowledge the user needs to know to accomplish their objective. The distance between the user’s knowledge and target knowledge is “the gap”; and this is where design happens.
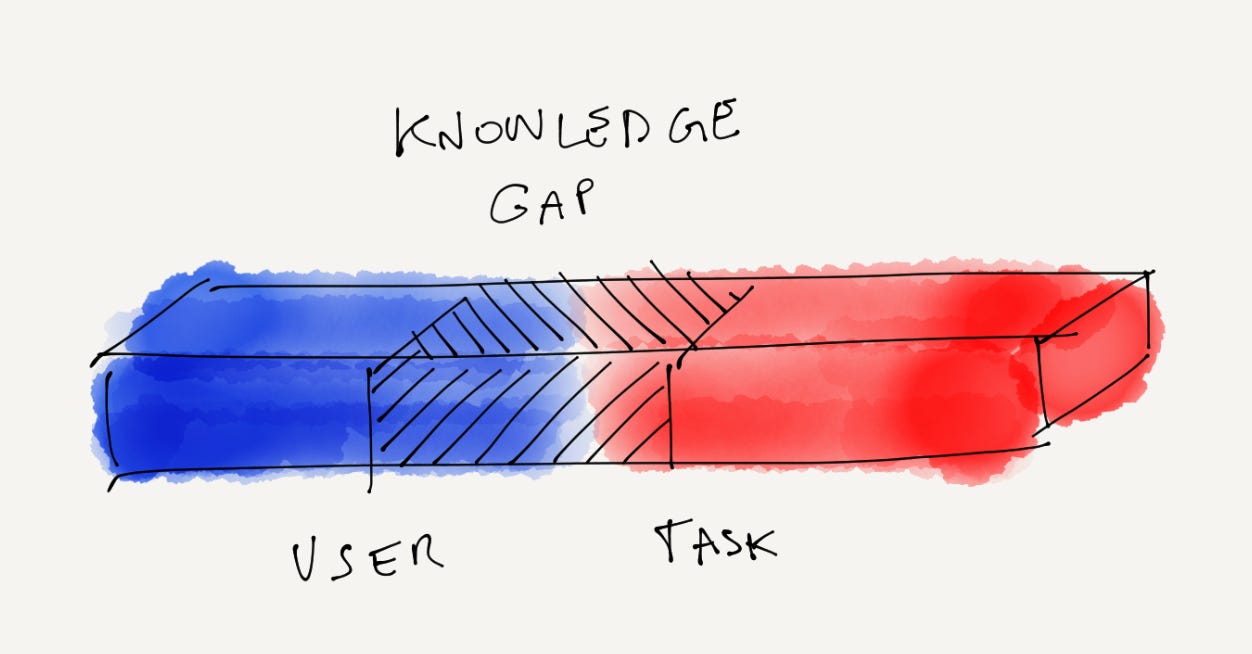
We don’t need to design to the left of the current knowledge point, because it’s all stuff the user already knows. And we don’t need to design things to the right of the target knowledge point since the user won’t be needing that information (for this task, at least). We only need to design the interface for the space between current knowledge and target knowledge.
The goal of a user interface for any given task is to make sure these 2 dimensions are closest as possible because users can complete their objective when current knowledge equals target knowledge. And that’s about it.
How are we going to make that happen?
If you think about it, there are only two possible ways to make that happen. You either increase your users’ knowledge until they know everything they need to know, or you decrease the amount of knowledge necessary to use your product until target knowledge only requires the information the users already have.
The question for the designer becomes a straightforward one: do you train your user or do you reduce the need to learn something?
The key here is not to design something for the average, but to give to each his own desired experience. In other words, given a specific task, users on the lower part of the spectrum either need some training to do the task or some abstraction that makes it relatively easy to do without the extra knowledge.
A reasonably good approach to design our web3 product would be to plot the user pool and their expected level of knowledge against the tasks at hand and the required level of knowledge. Once the gap is clear, it’s suddenly much easier to understand how to practically diversify the experiences.
For example, to increase the knowledge of newbies, you can consider all kinds of things that bake education into the product experience.
Think about:
Blitzcourses: flash courses where the app itself incentivizes users to learn about the crypto fundamentals
Assessment quizzes: quizzes like for news users to understand their fluency and program the experience accordingly with more or less guidance during setup and in-app use
Contextual popovers or things like “tip of the day” to encourage incremental learning
Instead, if you prefer to diminish the amount of knowledge required for a newbie to complete a given task, you can think about abstract complexity layers.
For this matter, you can consider:
Avoiding crypto-specific vocabulary
Tapping into flows and UX that users are already familiar with from established fintech or general baking apps
Providing a “sandbox” where users can simulate tasks and learn from perceptual experience without the risk of doing something unsafe
Part III: Build transformative worlds, not tools
I’ve started this post by talking about the differences between web3 from a technical and ethical perspective. The idea is well-intentioned but fundamentally flawed if we treat crypto - or technology in general - like an end-game, rather than serving users and getting results.
Which behaviors, and which experiences does crypto unlock? And more importantly, which human desires are more attainable as a result of this?

People aren’t interested in tools. They’ve actually never been.
We use the internet because it makes things more convenient, not because we think it’s an interesting piece of technology. The internet is a giant machine that eliminates friction between us and the things that we want.

As humans, we want the things that we’ve always wanted. We want love, status, and money. We want to influence and create things, and have a sense of belonging, and mattering. We want to have confidence and self-fulfillment, and we want answers and solutions and we want stuff.
If we think about it, we realize that the most successful products on the Internet have all learned to fulfill the same set of desires more conveniently than their predecessors.
So it is fundamental that we focus less on the tools and technical underpinnings, and more on the context where these tools live. It’s the world in which the tool lives where there’s sustained value for the users.
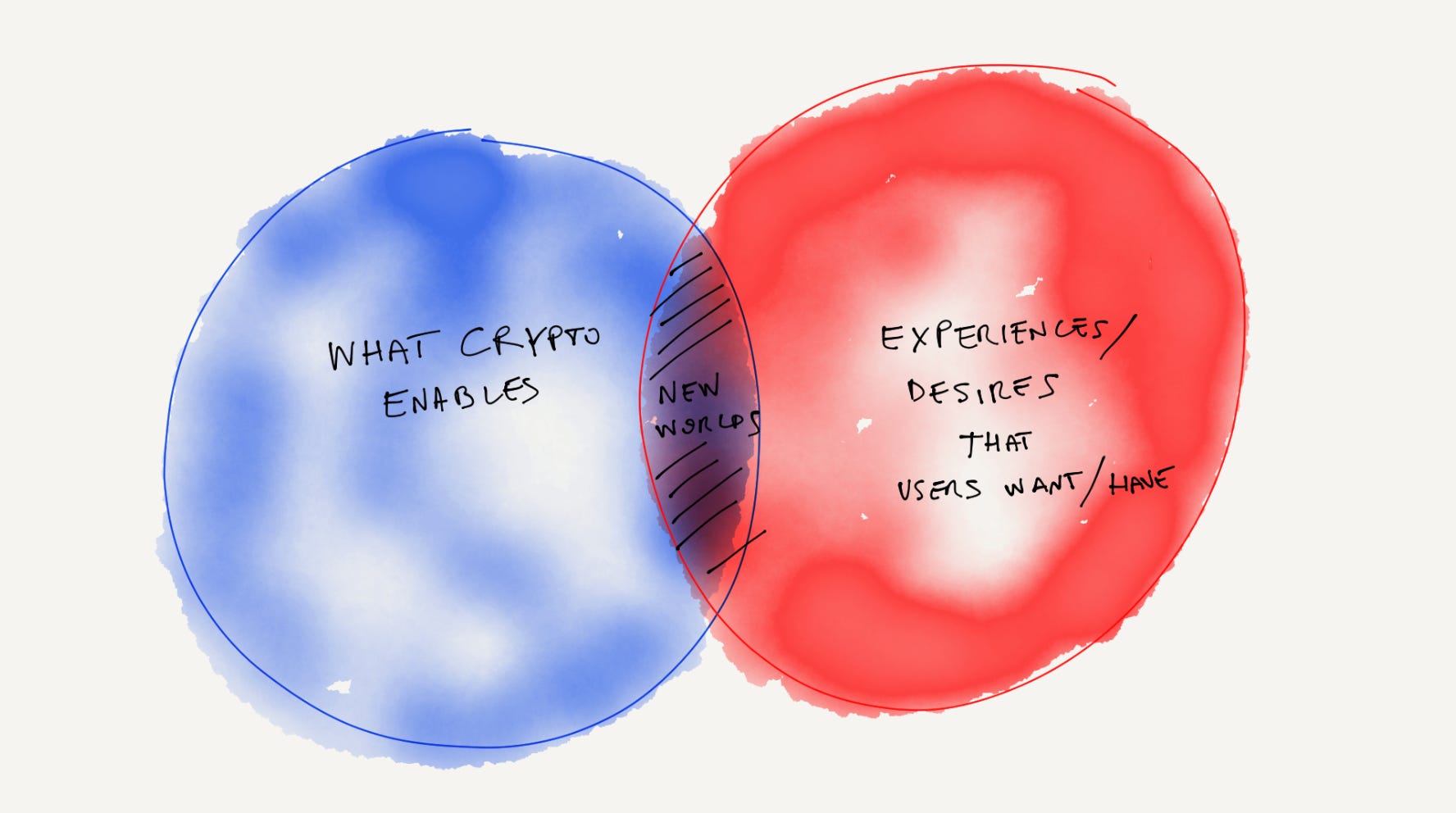
What are the worlds that are worth creating? And how do they bring users to new dimensions? And what can users actually do in those worlds? From visual art and music to code, design, and knowledge or education, the opportunity here is to craft new, extraordinary experiences and make a new set of human behaviors more attainable.
Conclusions
As we’re seeing, the crypto market can be very volatile and its cycles seem chaotic. People who’ve been in crypto for a while know well this alternating between periods of euphoria and speculation and the so-called “crypto winters.”
But an important point is that speculation is installation. Without people speculating that this thing could be big, it wouldn’t have had a price. Without it having a price it couldn’t be treated as money. Without it being treated as money, people wouldn’t have new ideas, and there couldn’t be any of these up-and-coming projects and apps.
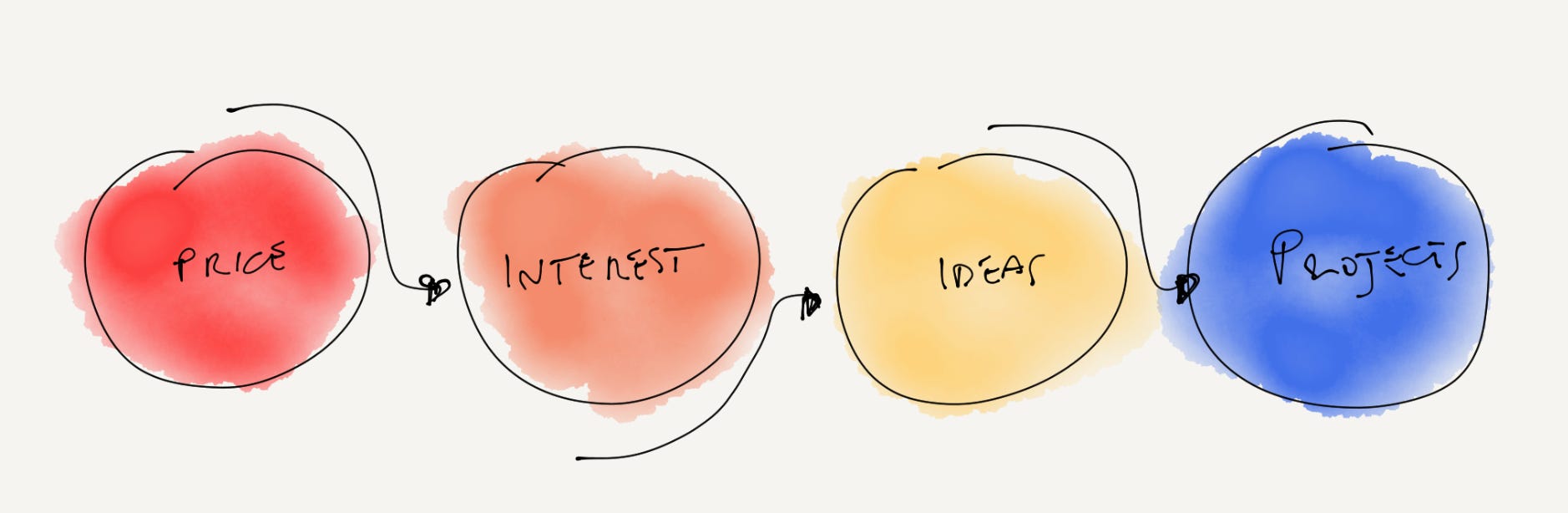
Similarly, after the dot-com crash in the early 2000s, many questioned the need for all the bandwidth that had been built out in the years prior. What was the point of getting emails a little faster? In the mid-2000s, applications like YouTube were made possible because of that innovation, kicking off a new era for internet entrepreneurs.
Crypto is in the middle of finding its purpose and blockchains could be in a similar place, with the breakout on the horizon for those who are willing to play the long game.
Not all applications that deal with crypto are decentralized applications. There are plenty of centralized apps like Coinbase that depend on either private or cloud (AWS in the case of Coinbase) servers.
Here I am mostly referring to the Ethereum blockchain. Generally speaking, everything I said here holds true for programmable, multi-purpose blockchains and not, for example, the Bitcoin blockchain who is intended primarily for exchanging and storing value.
There are solutions to these problems, but until Ethereum 2.0 gets rolled out take latencies for granted.